LiteFlow——高效的工作流编排库
更新: 6/11/2026 字数: 0 字 时长: 0 分钟
最近公司有一些工作流相关的任务,让我提前学习一下,最近把他的文档看了一下,也算有些理解,这里写下和大家一同分享
LiteFlow的意义
LiteFlow旨在简化工作流的实现复杂度,这里我们需要先了解工作流是什么
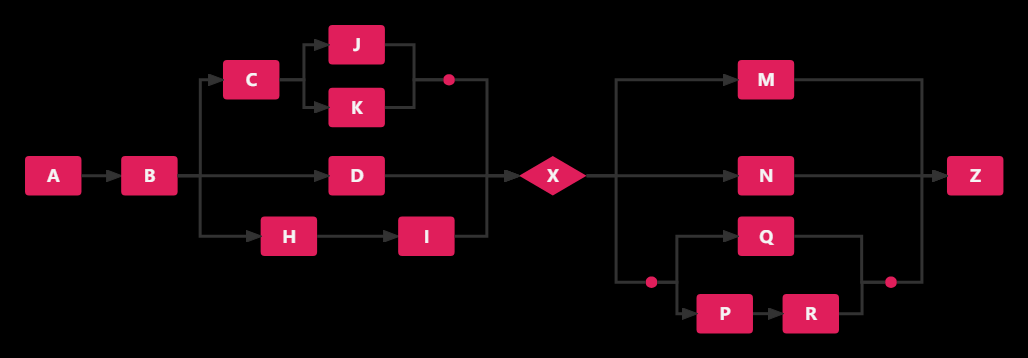
像上图中(官网图)这样的流程图就是一个工作流,我们可以使用原始的方法调用的方式实现,但是这样会导致代码的高度耦合,于是我们就尝试使用别的方式来降低耦合度,这就是工作流
在LiteFlow种,我们将上图中的节点定义为Node,图的整体结构则由XML进行编排,最终在代码中通过FlowExecutor来进行链的调用
基本配置
然后简单的配置一下yaml文件,这里主要是让Spring知道我们的XML文件在resource文件下的哪个位置
节点的实现
在LiteFlow中,所有的节点全部继承自NodeComponent类,这个抽象类中存在必须要实现的方法process,这个方法中定义了节点在当前处应该如何执行
在SpringBoot环境下,我们需要使用LiteFlowComponent注解来将其注册为SpringBean,只有注册为SpringBean才可以让我们的Spring来托管我们的节点,同时方便的使用Spring的任务管理
import com.yomahub.liteflow.annotation.LiteflowComponent
import com.yomahub.liteflow.core.NodeComponent
@LiteflowComponent("b") //这里的b是节点的名字,必须要定义
class BCmp : NodeComponent(){
override fun process() {
println("This is B CMP")
}
}值得一提的是,LiteflowComponent注解继承自Component,这也就表明我们的节点本质就是一个Component
根据节点类型的不同LiteFlow实现了多种不同的节点类,我们都可以通过继承来实现我们需要的节点,具体内容参考文档
另外,我们还可以使用声明式组件的方式来定义节点,官网提到这种方式的出现是为了解决Java只能单继承的问题,即节点实现占用了唯一的继承位置(当然,我们可以手写中间类来实现继承的传递,不过这就有些麻烦了)
声明式组件取消了使用继承来实现节点,而是使用注解来实现,但是方法级的节点声明有违开闭原则,因此若非必要不推荐使用方法级的节点声明
类级别的节点声明会在后续将上下文时有大作用
EL规则
EL规则是LiteFlow用于实现图整体编排的方法,其核心作用是将节点链接为一个完整的图,在LiteFlow中,EL规则一般是由XML来进行实现
<chain name="chain1">
THEN(s1)
</chain>其中name是chain的名字,而s1则是节点的名字,Liteflow中存在大量自定义的EL语法,这里可以自行浏览官网中的内容
编排复杂图
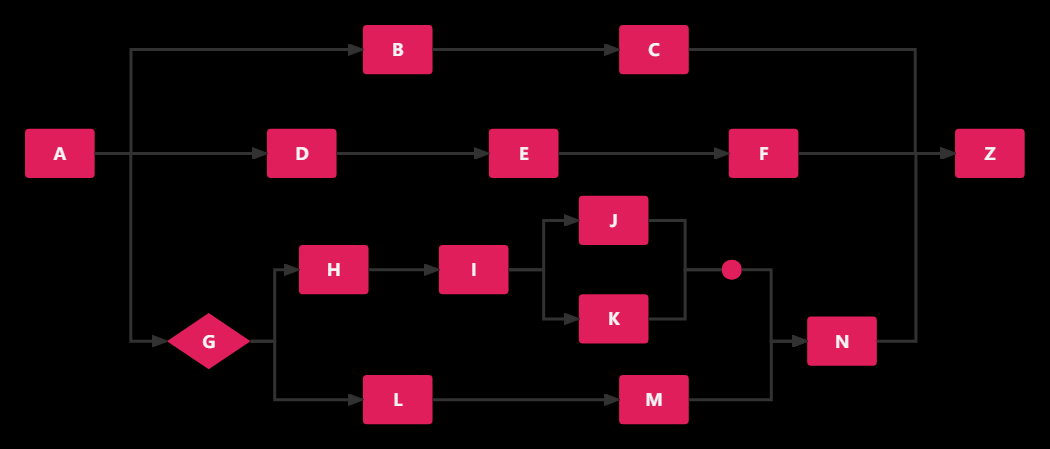
上图我们就可以使用EL规则来实现,但是该图过于复杂,使用EL表达式编排出来的结果可能长这样
<chain name="chain1">
THEN(
A,
WHEN(
THEN(B, C),
THEN(D, E, F),
THEN(
SWITCH(G).to(
THEN(H, I, WHEN(J, K)).id("t1"),
THEN(L, M).id("t2")
),
N
)
),
Z
);
</chain>这种EL表达式写出就变得极难维护,LiteFlow为了解决这个问题提出了子变量的方式,我们可以将一个EL表达式作为一个变量写在chain标签中,然后通过组合自变量的方式实现复杂图
在使用了自变量的方式下,我们上面的XML图就变成了下面这样
<chain name="chain1">
item1 = THEN(B, C);
item2 = THEN(D, E, F);
item3_1 = THEN(H, I, WHEN(J, K)).id("t1");
item3_2 = THEN(L, M).id("t2");
item3 = THEN(SWITCH(G).to(item3_1, item3_2), N);
THEN(
A,
WHEN(item1, item2, item3),
Z
);
</chain>拓展用法
EL表达式支持重试机制,我们可以使用retry方法来实现一个节点/链的错误重试
<chain id="chain1">
THEN(a, b).retry(3);
</chain>
<chain id="chain2">
FOR(c).DO(a).retry(3);
</chain>
<chain id="chain3">
exp = SWITCH(x).to(m,n,p);
IF(f, exp.retry(3), b);
</chain>
<chain id="chain4">
THEN(a, b.retry(3));
</chain>
<chain id="chain5">
THEN(a, b).retry(3, "java.lang.NullPointerException", "java.lang.ArrayIndexOutOfBoundsException");
</chain>值得一提的是,上面的chain5的作用是只在指定的异常出现时才进行重试
超时规则语法
我们可以使用 maxWaitSeconds,maxWaitMilliseconds 关键字可对任意的组件、表达式、流程进行超时控制
maxWaitSeconds后面传的是秒数,maxWaitMilliseconds后面传的是毫秒数。使用方式都一样。
maxWaitSeconds和maxWaitMilliseconds 传入一个 int 类型的整数表示最大等待秒数/毫秒数,使用如下方法设置最大超时等待时间。
<flow>
<!-- 串行编排超时控制 -->
<chain name="then">
THEN(a,b).maxWaitSeconds(5);
</chain>
<!-- 并行编排超时控制 -->
<chain name="when">
WHEN(a,b).maxWaitSeconds(3);
</chain>
<!-- 循环编排超时控制 -->
<chain name="for">
FOR(2).DO(a).maxWaitSeconds(3);
</chain>
<chain name="while">
WHILE(w).DO(a).maxWaitSeconds(3);
</chain>
<chain name="iterator">
ITERATOR(x).DO(a).maxWaitSeconds(3);
</chain>
<!-- 选择编排超时控制 -->
<chain name="switch">
SWITCH(s).TO(a, b).maxWaitSeconds(3);
</chain>
<!-- 条件编排超时控制 -->
<chain name="if">
IF(f, b, c).maxWaitSeconds(3);
</chain>
<!-- 组件超时控制 -->
<chain name="component">
WHEN(
a.maxWaitSeconds(2),
b.maxWaitSeconds(3)
);
</chain>
<!-- 流程超时控制 -->
<chain name="testChain">
THEN(b)
</chain>
<chain name="chain">
testChain.maxWaitSeconds(3);
</chain>
</flow>关于分号
LiteFlow不加分号是可以运行的,但是官方推荐我们每一句表达式都在末尾加上分号,这是因为在使用自变量的情况下不使用分号会出错
关于注解
在LiteFlow的EL规则写法里,注释从2.13.0开始,只支持/** **/这种注释,不支持单行注释//
因此所有注解推荐使用/** **/
<chain name="chain1">
THEN(
/**
* 我是多行注释
* 我是多行注释
**/
WHEN(c, d)
)
</chain>
<chain name="chain2">
THEN(
a,b,
/** 我是注释 **/
WHEN(c, d)
)
</chain>chain2无法编译,这是因为表达式中间夹杂注释
执行chain
@SpringBootTest
class LiteflowDemoApplicationTests(){
@Resource
private lateinit var flowExecutor: FlowExecutor
@Test
fun contextLoads() {
val response = flowExecutor.execute2Resp("chain1", "arg", DefaultContext::class.java)
}
}在SpringBoot环境中,我们需要使用@Resource注解引入FlowExecutor类来执行我们的chain(特别注意,这个Bean没法直接用@Autowired引入)
FlowExecutor是我们的chain执行器,其中的execute2Resp就是执行chain所必须的方法,特需要我们传入至少3个参数:
- chain的名字,类型为String
- 初始传入到chain中的值,类型为Object
- 上下文,作为最后一个参数,本质为一个可变参数,因此可以传入多个,类型为Class,也就是具体类的反射
这里的后两个参数的含义后面都会讲解,这里我们优先关注FlowExecutor
FlowExecutor通过封装一个线程池完成实现,我们可以通过修改配置文件来修改一些默认线程池配置
# 修改线程池线程数量
liteflow.main-executor-works=64
#修改线程池实现
liteflow.main-executor-class=com.yomahub.liteflow.thread.LiteFlowDefaultMainExecutorBuilder另外如果我们使用的是JDK21以上的版本,还可以开启虚拟线程进行进一步的优化
# 默认为true
liteflow.enable-virtual-thread=falseFlowExecutor中执行chain的默认方法是flowExecutor.execute2Resp,其返回的LiteflowResponse中含有整个链路最终执行的状态
如果我们想要动态的观察链执行的结果,则可以使用flowExecutor.execute2Future方法,传入参数与execute2Resp一致,但其返回值会转变为Future类,Future类内部封装一个LiteflowResponse,我们可以使用熟悉的多线程方式操控Future,flowExecutor.execute2Future方法也为异步方法
初始参数
FlowExecutor.execute2Resp的第二个参数为初始参数,这个参数是你在外部想要传送给链的值,这个值可以通过NodeComponent中封装的 getRequestData()来获取
@LiteflowComponent("a")
public class ACmp extends NodeComponent {
@Override
public void process() {
YourBean requestBean = this.getRequestData();
}
}上下文
为了实现多个节点之间参数的传递,LiteFlow引入了上下文,这也就是FlowExecutor.execute2Resp中的最后一个参数
上下文通过NodeComponent中的getContextBean方法获得
@LiteflowComponent("yourCmpId")
public class YourCmp extends NodeComponent {
@Override
public void process() {
CustomContext context = this.getContextBean(CustomContext.class);
//或者你也可以用这个方法去获取上下文实例,如果你只有一个上下文,那么和上面是等价的
//CustomContext context = this.getFirstContextBean();
...
}
}上下文可以传递多个,同样都是使用getContextBean获取
不过很明显的是,上面这种写法有违迪米特法则,因此LiteFlow引入了上下文参数注入的方式来解决这一问题
上下文参数注入目前只支持声明式组件,这里推荐类级别式声明
一个普通的类级别声明式组件一般长这样:
@LiteflowComponent("a")
public class ACmp{
@LiteflowMethod(LiteFlowMethodEnum.PROCESS, nodeType = NodeTypeEnum.COMMON)
public void processAcmp(NodeComponent bindCmp) {
YourContext context = bindCmp.getContextBean(YourContext.class);
//从context中取到业务数据进行处理
User user = context.getUser();
}
}我们一般是从bindCmp中获取的ContextBean,而为了实现解耦,我们实际可以通过上下文参数注入来直接获取想要的上下文字段
@LiteflowComponent("a")
public class CmpConfig {
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS, nodeType = NodeTypeEnum.COMMON)
public void processA(NodeComponent bindCmp,@LiteflowFact("user") User user) {
user.setName("jack");
}
}我们只需要给入参加上@LiteflowFact注解即可获取到想用的上下文参数,具体是多个上下文中哪个的参数将会由LiteFlow自行解析,如果有多个上下文有同样的字段,则会使用执行链时顺序传入的第一个含有指定字段的上下文中的字段
对于多层的参数,我们还可以通过点操作符获取
@LiteflowComponent("a")
public class CmpConfig {
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS, nodeType = NodeTypeEnum.COMMON)
public void processA(NodeComponent bindCmp,
@LiteflowFact("user.name") String name,
@LiteflowFact("data1") String data1) {
//do biz
}
}当然在有多个上下文拥有同样的属性的时候,你也可以指定上下文,例如这样:
@LiteflowComponent
public class CmpConfig {
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS, nodeType = NodeTypeEnum.COMMON, nodeId = "a")
public void processA(NodeComponent bindCmp,
@LiteflowFact("orderContext.id") Integer orderId
@LiteflowFact("memberContext.id") Integer memberId) {
//do biz
}
}如果我们的节点想要给上下文设置参数,则可以使用NodeComponent中实现的setContextValue方法
@Component("a")
public class ACmp extends NodeComponent {
@Override
public void process() {
String name = this.getContextValue("name");
this.setContextValue("setDesc", "hello," + name);
}
}其传入参数的具体内容与上下文参数注入的注解value值一致
脚本语言
LiteFlow支持使用脚本语言来实现节点的声明,这一功能是为了实现链的热更新,我们可以引入Nacos来支持LiteFlow,在Nacos的加持下,我们的EL表达式的文件是可以写在Nacos的配置文件中的,而Nacos的配置文件支持热重载,进而我们就可以实现链的热重载