Spring Modulith——从一个管理工具到代码规范的思考
更新: 9/28/2025 字数: 0 字 时长: 0 分钟
老的伪MVC的架构模式在现代开发和大型项目开发中已经很难做到维护项目的高内聚低耦合,我们更希望能够通过一种模块化的方式来提高代码的质量。
Spring Modulith 是 Spring 公司出品的,用于帮助开发者更好的实现领域驱动设计的工具。
在Spring Modulith 的帮助/规范下,我们可以写出一种更加高质量的模块化的代码
基本使用
Spring Modulith 会自动的帮我们对包进行管理,它默认与启动类相同目录的包是一个模块,且只有模块中最外层的类可以被其他模块调用
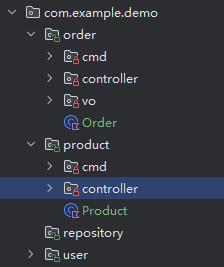
像这个代码分层中,只有最外层的Order,Product 可以被别的模块调用,这也是我们的聚合根,用来处理业务问题,在跨聚合业务中可能会被别的聚合下的cmd类使用到,因此应该作为该模块唯一被暴露出去的类
同样的,我定义了一个repository包,这个包用于来存放我们的仓储类,由于仓储和我们的具体业务无关,只是单纯的为了存放数据到不同的数据库中,因此也单独被设置为一个模块,我们任何模块的cmd类都可以使用并且调用他
访问问题
此时就会引入一个新的问题——如果存在多个数据库的问题
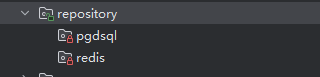
那么我们的模块下可能是这样,但是这就导致了我们的仓储无法被领域模块使用
为了解决这个问题Spring Modulith提供了两种解决方案
命名接口
@NamedInterface("redisRepository")
@PackageInfo
class RedisRepository {
}我们可以使用@NamedInterface+@PackageInfo注解为这个类提供一个名字,在这种情况下,这个类同一个包下的所有类均可被外界访问
开放模块
@ApplicationModule(type = Type.OPEN)
@PackageInfo
class MoudleMeta {
}或者也可以像这样,在模块(也就是和启动类同一目录下的包)中放入一个这样的类,这也就表明1了这个模块是开放的,他下面的类可以被其他的模块自由的访问
为什么老的代码结构难以实现好的管理
在老的代码中,我们的业务逻辑可能大量的存在与一个Service类中,所有的业务都由Service和Service之间的互相调用完成,而数据类只是承载数据的贫血模型,其除了承载数据之外没有任何意义
除此之外还有在Service中大量的使用mp提供的查询构造器,而舍弃掉使用Repository,这实际上是将Repository(实际上并不是真正意义上的Repository,因为没有涉及聚合根的构建,只是单纯的将数据库表映射为Java Bean)的任务变相的交给了Service来处理,而所谓的Dao变成了一个用于作为代码于数据库访问的”大门“(一个很薄弱的,没有什么作用的门),提供几个访问数据库的api,而具体访问后的操作(大部分都是构建SQL)却被强制安排在了Service中
而在Spring Modulith的要求下,我们强制的只能把少量的类放在模块根目录(比如我们的聚合根),这就要求我们把代码都集中在聚合根中(当然,你也可以把传统意义上的Service类或者更多的类放在根目录,但这也就失去了我们模块化的意义)
而由于我们的业务大部分又存放于Cmd类中,这就表示我们真正能运用的和业务相关的类只有各种聚合根
于是我们的代码就会强制让我们的思考逻辑变成:
获取聚合根
使用聚合根完成业务操作
这个过程强制了程序员必须将代码限制在一个对象中,并且只能通过使用对象持有的方法的形式来完成自己的业务目的,同时我们的对象(聚合根)中又同时承载着业务的值,所以我们就很自然的写出了充血模型
有些细心的小伙伴们可能已经发现了一个问题,那就是上面的过程没有数据库相关的内容,这也正是我们希望的
在OOP开发中,我们的项目理应是围绕Object来进行实现,而老架构中,我们是围绕Database来进行实现的(DOP?),我们的程序员被”如何去读取数据返回给前端?“,“如何将前端给的数据写入数据到数据库中?”一类的问题所困扰,而无法将自己全部的心智放在解决业务问题上。
在早期开发中,这或许能带来更加高速的开发体验,但是时间久了,你会发现代码的耦合越发严重,甚至程序员已经难以对代码进行迭代和维护,这本质上是我们将过多的心智放在了数据库上,而我们的项目代码上
而在Spring Modulith的要求中,我们的思考从如何获取数据库对象转变为了如何获取聚合根,而聚合根又是业务的体现,因此这也让我们转变思考方向到业务上
现在,我们可以扩充一下上面的思考逻辑,以便加上对数据库的处理:
如何使用前端或已有的数据构建出一个聚合根
如何使用聚合根完成业务操作
如何将聚合根持久化(一般是转换为一个或多个数据库对象进行存储)
可以看到,我们可以看到,聚合根实际上并非是和数据库关联的,正如DDD想要的一样,聚合根是问题域在代码中的体现,其作用是为了解决问题,而非如何查询或是存储
这里我来展示一下我写的一个简单的聚合根
data class Order(
val id: Int,
val user: String,
val purchases: MutableMap<Int,Purchase>,
val createTime: LocalDateTime
)
data class Purchase(
val productName: String,
val singlePrice: Double,
val number: Int
)这是一个订单业务的聚合根,其中purchases是一个值对象(VO/Value Object),表示订单上的商品
在老的架构中这几乎不可能出现,因为purchases: MutableMap<Int,Purchase >无法被数据库直接映射,这也就使其无法成为代码的中心,顶多可能会以一个DTO/Request/VO(View Object)类的形式出现,用于承载前端或是中间转载的数据
然而实际上,如果我们只考虑业务,我们会发现这样的一个对象其实才更加合理,因为我们业务中的订单就是和我们的Order对象一致的,有id,用户名,购买的商品,以及购买的时间,很自然的与业务相对应,也不用做额外的转换
我们是如何构建出这样的聚合根的呢?实际上很简单,只是因为我们没有考虑数据库映射的难度,只是单纯的从业务出发(当然,真正的业务中一个聚合根的出现需要复杂的建模)
然后,我们就会很自然的发现,好像大部分订单相关的代码都只需要在Order这个聚合根中完成(比如计算订单总价,添加或者减少商品)
因此这个聚合根就会变成充血的
data class Order(
val id: Int,
val user: String,
val purchases: MutableMap<Int,Purchase>,
val createTime: LocalDateTime
){
fun getTotalPrice()= purchases.entries.sumOf { it.value.singlePrice*it.value.number }
fun getTotalNumber(id: Int)= purchases.remove(id)
fun addPurchase(id:Int,purchase: Purchase)=purchases.put(id, purchase)
}
data class Purchase(
val productName: String,
val singlePrice: Double,
val number: Int
)我们的业务直接在聚合根中完成,而Cmd类只需要构建聚合根(手动创建或者使用Repository获取)并使用其类即可
这样我们的代码就被高度复用在了聚合根中,并且对数据库相关的操作被屏蔽在了核心代码之外,这也就使得我们获得了更加高质量的代码