Prompt工程
更新: 5/5/2026 字数: 0 字 时长: 0 分钟
特别鸣谢各位论文的作者
总所周知,大模型的核心能力是next token prediction,即给定上文,推断出下一个token,而Prompt就是我们这里的上文
Prompt功能之所以有效,是因为LLM在实际生产中出现了一个惊人的能力——In-Context Learing(ICL,上下文学习)
虽然上下文学习为什么会出现在学术届仍有争议,但是ICL的结论是一样的:“Prompt的内容和格式直接决定了模型的行为”,这就是Prompt工程的理论基础
Prompt的工程价值层级
| 层级 | 技术 | 适用场景 | 实现复杂度 |
|---|---|---|---|
| 基础 | Zero-Shot(零样本,对于生产意义不大), System Prompt(系统级提示词) | 简单问答、格式控制 | 低 |
| 进阶 | Few-Shot(少量样本,即Prompt中给出你想要的结果), Output Format(规定输出格式) | 分类、抽取、翻译 | 中 |
| 推理 | CoT(Chain of Thought,主动让AI思考), Self-Consistency(多次采样,获取最优答案) | 数学、逻辑、代码 | 中 |
| 高级 | ToT(思维树), ReAct(重思考), Structured Output(结构化输出) | 复杂推理、Agent | 高 |
模型设置
在进行Prompt之前,我们首先要先了解以下模型设置,在使用大模型API的时候,我们可以同v过设置一些参数来让大模型尽可能的给到我们想要的结果
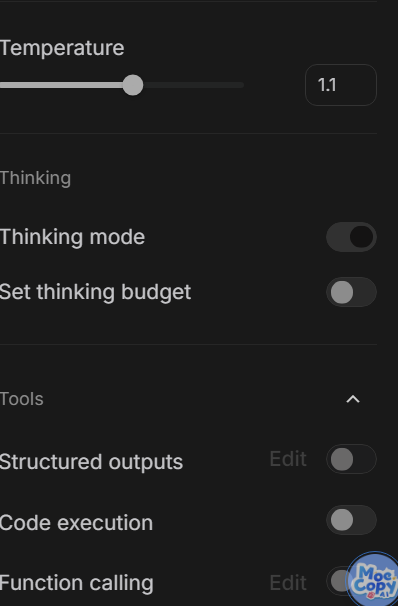
- temperature:温度,或者可以理解成情感指数,当该参数越高时,AI会更加具有创意的进行回答,较为适合文学创作,当temperature较低时,AI会更加严谨的回答,比较偏向于工程操作
- Top-p:AI回答的范围,如果你将数设置的越小,AI将会在越有限/相关的内容进行回答,如果你将参数设置的较大,AI会在更加广泛/偏差的内容进行回答
- Max Length:最大回复Token数
- Frequency Penalty:重复度惩罚,尽可能让AI在后续的Token中不生成前面重复的内容
- Presence Penalty:重复度惩罚,但是和Frequency Penalty的惩罚机制不同,Presence Penalty的惩罚机制是认为重复十次的Token和重复两次的Token收到的惩罚是一样的此设置可防止模型在响应中过于频繁地生成重复的词。 如果您希望模型生成多样化或创造性的文本,您可以设置更高的
presence penalty,如果您希望模型生成更专注的内容,您可以设置更低的presence penalty。
在使用过程中,temperature和Top-p一般只修改一个,Presence Penalty和Frequency Penalty一般也只修改一个
Zero-Shot Prompt——零样本提示
所谓的零样本提示,就是不加篇幅的进行提示,直接给模型一个指令,不提供任何示例,我们平日里写的大部分的Prompt都是Zero-Shot Prompt
一个常见的Zero-Shot Prompt的示例
将以下文本翻译成英文: 今天天气很好,我想去公园散步现代的大模型经过SFT和RLHF对齐之后,基本上可以用Zero-Shot解决用户在现实中遇到的大部分问题
Zero-Shot的效果高度依赖模型本身,其优势显而易见,就是容易书写,但同样的,他也有很多的问题:
- 非标准任务:模型在预训练中没有见过类似模式的任务(如自定义的分类体系)
- 精确格式要求:需要严格遵循特定的输出格式(如 JSON Schema)
- 复杂推理:需要多步推理的数学或逻辑问题——模型倾向于直接给出答案而非逐步推导,导致错误率高
让AI思考起来
Takeshi Kojima et al.(2022)提出了一个发现,那就是在Prompt的末尾加上一句“Let‘s think step by step”(让我们一步步思考)可以有效的降低AI回答问题的错误率
再加上了这句Prompt后,AI会展开推理过程:“首先...然后...因此...”,每一步的输出都为下一步的推理提供了内容,显著降低了错误绿
这个过程让中间推理步骤作为”工作记忆”被写入上下文,为后续推理提供了额外的信息,这也是自回归语言模型的特性所致,即每一个token的生成都依赖于前文
Zero-Shot-CoT 揭示了 LLM 的一个根本性质:模型的推理能力受限于生成步数,而非模型大小。让模型”说出”推理过程,本质上是增加了推理的”计算步数”——每个生成的 token 都是一次额外的前向传播,都能进行一步推理。这就是为什么”思维链”能显著提升推理任务的性能,思考模式往往会得到更好的结果
Few-Shot Prompting——少样本提示
Few—Shot Prompting往往是在Prompt中提供少量(2~8个)的输入输出示例,让模型通过In-Context Learning“学会”任务的模式
提问:
将以下电影评论分类为"正面"或"负面":
评论:这部电影太精彩了,演员表现出色!
分类:正面
评论:剧情拖沓,浪费了两个小时。
分类:负面
评论:特效还可以,但故事缺乏新意。
分类:
输出:
分类:负面Few-Shot的效果对示例的选择高度敏感,研究发现:示例的多样性比示例的数量更重要。3 个覆盖不同模式的示例(正面/负面/中性)往往优于 8 个同质化的示例
同样的,示例的顺序也会显著的影响结果,Lu et al.(2022)发现,仅仅改变示例的顺序,同一模型在同一任务上的准确率可以从接近随机(~50%)波动到接近最优(~90%)
一般建议:
- 将与目标输入最相似的示例放在最后(靠近要预测的位置)
- 在分类任务中,平衡各类别的示例数量
- 避免连续出现同一类别的示例
Few-Shot的适用场景
| 场景 | 是否适合 Few-Shot | 原因 |
|---|---|---|
| 文本分类 | 非常适合 | 模式明确,少量示例即可定义任务 |
| 信息抽取 | 适合 | 示例展示提取模式 |
| 格式转换 | 适合 | 示例定义输入/输出格式 |
| 翻译 | 适合(特定领域) | 通用翻译 Zero-Shot 即可,领域术语需示例 |
| 数学推理 | 需要 CoT | 纯 Few-Shot 不够,需结合思维链 |
| 开放式生成 | 不太适合 | 示例可能限制生成的多样性 |
动态Few-Shot(Retrieval-Augmented Few-Shot)
动态Few-Shot根据当前输入,从一个示例库中检测到最相似的示例,动态构建Prompt
实现方式:将所有示例用 Milvus 等向量数据库索引(用 Embedding 模型编码),对每个新输入做向量检索,取 Top-K 最相似的示例插入 prompt
这一想法类似RAG,本质上都是用检索来增强 prompt 的质量
另一方方面,我们还必须知道:
- “标签空间和演示指定的输入文本的分布都很重要(无论标签是否对单个输入正确)”
- 使用的格式也对性能起着关键作用,即使只是使用随机标签,这也比没有标签好得多。
- 其他结果表明,从真实标签分布(而不是均匀分布)中选择随机标签也有帮助
因此即时样本中存在错误,其效果也比没有样本好(当然,不能全是错误)
Few-Shot的限制
Few-Shot虽然十分有效,但是在一些场景上并不适用,一个典型的场景就是数学技算,看下面这个例子
提示:
这组数字中的奇数加起来是一个偶数:4、8、9、15、12、2、1。
A:答案是False。
这组数字中的奇数加起来是一个偶数:17、10、19、4、8、12、24。
A:答案是True。
这组数字中的奇数加起来是一个偶数:16、11、14、4、8、13、24。
A:答案是True。
这组数字中的奇数加起来是一个偶数:17、9、10、12、13、4、2。
A:答案是False。
这组数字中的奇数加起来是一个偶数:15、32、5、13、82、7、1。
A:输出:
答案是True。会出现这样的结果是因为少样本提示只给了模型 [输入] -> [最终答案],这是一个结果导向的过程,模型更多的是学习到了该如何回答,而并非该如何计算,因此我们会发现模型给我们的是一个格式正确但答案可能有问题的结果,这就是因为模型并没有学到中间的计算过程
对于这种过程导向的问题,现在主流的方案往往是采用思维链(CoT)来解决
CoT——思维链推理
CoT(Wei et al.,2022)是Prompt工程中的重要突破之一,它在 Few-Shot 示例中不仅展示”输入→答案”,还展示了从输入到答案的完整推理过程
不使用 CoT 的 Few-Shot:
Q: Roger有5个网球。他又买了2罐网球,每罐有3个。他现在有多少个网球?
A: 11
Q: 食堂有23个苹果。如果他们用掉了20个并又买了6个,他们有多少个苹果?
A:使用 CoT 的 Few-Shot:
Q: Roger有5个网球。他又买了2罐网球,每罐有3个。他现在有多少个网球?
A: Roger一开始有5个网球。2罐网球,每罐3个,共2×3=6个。5+6=11。答案是11。
Q: 食堂有23个苹果。如果他们用掉了20个并又买了6个,他们有多少个苹果?
A:CoT将模型的推理过程放到了回答中,模型后面输出的每一个Token都会参考前面的推理过程,在这个过程中,CoT会将复杂的问题拆分为简单的子问题,输出的中间结果会作为大模型的记忆(或者说是上下文),这里面的信息会在后续被使用到,即时出现了错误,由于自回归语言模型的Self-Attention机制,他也能即时的访问到错误的地方,然后及时的进行改正
CoT的适用条件
CoT也并非对于所有的情景都适用,Wei et al.的研究发现,CoT的主要收益在于:
- 需要多步推理的任务:数学应用题、逻辑推理、代码生成、多跳问答
- 大模型(>10B 参数):小模型(<10B)使用 CoT 反而可能降低性能——因为小模型的推理能力不足以生成正确的中间步骤,错误的中间步骤反而会误导后续推理
对于简答的任务,CoT的收效甚微,甚至还会加大负担
自动思维链
使用CoT的时候需要我们手动制作有效且多样化的例子(也就是人工编写多种问题的思考过程案例),这种手工的方式可能会导致次优解决方案”(Second-best solution,指在现实约束条件下无法实现最优目标,进而选择当前条件下能获得的最好替代方案)
Zhang et al.(2022)提出了一种消除人工的方法,即利用LLMs“让我们一步一步的思考”提示来让LLM生成一个接一个的思维链,这种自动过程仍然可能在生成的链中出现错误。为了减轻错误的影响,演示的多样性很重要,他们提出了Auto-CoT,它对具有多样性的问题进行采样,并生成推理链来构建演示
Auto-CoT 主要由两个阶段组成:
- 阶段1:问题聚类:将给定问题划分为几个聚类
- 阶段2:演示抽样:从每组数组中选择一个具有代表性的问题,并使用带有简单启发式的 Zero-Shot-CoT(添加“一步步思考”的提示) 生成其推理链
- 阶段3:采样: 把这些模型自己生成的步骤作为“少样本示例(Few-shot)”放进 Prompt 里。
简单的启发式方法可以是问题的长度(例如,60 个 tokens)和理由的步骤数(例如,5 个推理步骤)
这样最终的 Prompt 里的示例就是模型生成的,节省了人力,同时还是LLM适合阅读的模式
Sefl-Consistency——自我一致性
自我一致性(Wang et al.,2022)旨在“替换链式思维提示中使用的天真贪婪解码方法”,其想法是通过少样本CoT采样多个不同的推理路径,并使用生成结果选择最一致的答案,这有助于提高CoT提示在算术和常识推理的任务的性能
自我一致性基于一个直觉:正确的推理路径可能有多条,但他们应该指向同一个答案
具体做法:
- 对同一个问题,使用 CoT + 高温度采样(T>0)生成多个(如 5-20 个)不同的推理路径
- 从每个路径中提取最终答案
- 对所有答案做多数投票(Majority Voting),选择出现次数最多的答案
虽然我们的模型推理过程可能存在差异,但是往往结果都是一样的,因此如果多条路径都得到了相同的答案,那么这个答案大概率是正确的,但如果不同路径得到了不同的答案,那么就说明问题可能存在歧义或推理路径出现错误
Self-Consitency在数学和逻辑推理任务上通常比单次 CoT 提升 5-15% 的准确率。但代价是推理成本乘以采样次数——如果采样10条路径,成本就是单次CoT的10倍
在实际应用中,Self-Consistency 最适合对准确率要求高、对延迟不敏感的场景,如离线的数据标注、数学竞赛评测等。
链式Prompt
链式Prompt采用的是分治思想,他提出将一个大的问题拆分为多个小的问题,每个问题用来解决一些难点,最后汇总来解决原本的问题
例如,LLM 的一个常见用途是根据大型文本文档回答问题。想要更好阅读大文本文档,可以设计两个不同的提示,第一个提示负责提取相关引文以回答问题,第二个提示则以引文和原始文档为输入来回答给定的问题。换句话说,可以创建两个不同的提示来执行根据文档回答问题的任务
我们设计的两个问题应该是有前后关系的,前一个问题的回答会作为新的知识被模型用于解决下一个问题
一个常见的案例
提示 1:
你是一个很有帮助的助手。你的任务是根据文档回答问题。第一步是从文档中提取与问题相关的引文,由####分隔。请使用<quotes></quotes>输出引文列表。如果没有找到相关引文,请回应“未找到相关引文!”。
####
{{文档}}
####提示 1 的输出:
<quotes>
- Chain-of-thought (CoT) prompting[27]
- Generated knowledge prompting[37]
- Least-to-most prompting[38]
- Self-consistency decoding[39]
- Complexity-based prompting[41]
- Self-refine[42]
- Tree-of-thought prompting[43]
- Maieutic prompting[45]
- Directional-stimulus prompting[46]
- Textual inversion and embeddings[59]
- Using gradient descent to search for prompts[61][62][63][64]
- Prompt injection[65][66][67]
</quotes>在第一个提示中返回的引文现在可以用作下面第二个提示的输入。您可以对这些引文进行清理,比如移除引用标志。可以在提示链中新建另一个提示来移除或使用这些引用标志,但现在您可以忽略这些。然后,第二个提示接收由第一个提示提取的相关引文,并根据文档和这些提取的引文生成一个有帮助的回答。第二个提示可以是以下内容:
提示 2:
根据从文档中提取的相关引文(由<quotes></quotes>分隔)和原始文档(由####分隔),请构建对问题的回答。请确保答案准确、语气友好且有帮助。
####
{{文档}}
####
<quotes>
- Chain-of-thought (CoT) prompting[27]
- Generated knowledge prompting[37]
- Least-to-most prompting[38]
- Self-consistency decoding[39]
- Complexity-based prompting[41]
- Self-refine[42]
- Tree-of-thought prompting[43]
- Maieutic prompting[45]
- Directional-stimulus prompting[46]
- Textual inversion and embeddings[59]
- Using gradient descent to search for prompts[61][62][63][64]
- Prompt injection[65][66][67]
</quotes>提示 2 的输出:
文档中提到的提示技术包括:
1. Chain-of-thought (CoT) prompting[27]
2. Generated knowledge prompting[37]
3. Least-to-most prompting[38]
4. Self-consistency decoding[39]
5. Complexity-based prompting[41]
6. Self-refine[42]
7. Tree-of-thought prompting[43]
8. Maieutic prompting[45]
9. Directional-stimulus prompting[46]
10. Textual inversion and embeddings[59]
11. Using gradient descent to search for prompts[61][62][63][64]
12. Prompt injection[65][66][67]
每一种技术都采用独特的策略来增强或明确与大型语言模型的互动,以产生期望的结果。简化并创建提示链是一种有用的提示方法,其中响应需要经过多个操作或转换
ToT——思维树
CoT是线性的推理过程,但复杂的问题往往不是线性的——某一步可能有多个合理的选择,每个选择会导向不同的推理方向
ToT(yao et al.,2023)将推理过程建模为一个搜索树:
- 节点:推理的中间状态(“思考”)
- 分支:从一个状态出发的多种可能的推理方向
- 评估:让 LLM 自身评估每个节点的”前景”(这条路有没有希望得到正确答案)
- 搜索策略:BFS(广度优先)或 DFS(深度优先)遍历搜索树,剪枝掉没有前景的分支
Yao的文章中使用的是经典的24点游戏,这个游戏分为三个思维步骤,每一步都保留最优的五个选项
ToT 完成算 24 的游戏任务要执行广度优先搜索(BFS),每步思维的候选项都要求模型给出能否得到 24 的评估:“sure/maybe/impossible”(一定能/可能/不可能) 。
作者讲到:“目的是得到经过少量向前尝试就可以验证正确(sure)的局部解,基于‘太大/太小’的常识消除那些不可能(impossible)的局部解,其余的局部解作为‘maybe’保留。”每步思维都要抽样得到 3 个评估结果。整个过程如下图所示:
根据结果表明,ToT的表现大大超过了其他提示方法
Hulbert(2023)提出了思维树(ToT)提示法,将 ToT 框架的主要概念概括成了一段简短的提示词,指导 LLM 在一次提示中对中间思维做出评估。ToT 提示词的例子如下:
假设三位不同的专家来回答这个问题。
所有专家都写下他们思考这个问题的第一个步骤,然后与大家分享。
然后,所有专家都写下他们思考的下一个步骤并分享。
以此类推,直到所有专家写完他们思考的所有步骤。
只要大家发现有专家的步骤出错了,就让这位专家离开。
请问...System与角色设定
在对话过程中有一个特殊的消息,即System消息,用于设定模型的身份和行为准则,他在对话的开始前注入,持续的影响模型在整个对话中的行为
System Prompt 的本质是为模型提供一个”角色锚点”——后续的对话都在这个角色的框架下进行。一个好的 System Prompt 可以显著提升模型在特定领域的回答质量,因为它:
- 缩小了输出空间:模型不需要在所有可能的回答中搜索,只需要在”Python 工程师”角色的回答空间中搜索
- 激活了领域知识:模型的注意力被导向与 Python/FastAPI/PostgreSQL 相关的知识路径
- 建立了输出规范:明确了格式、风格和边界
System Prompt的设计原则:
明确角色身份:不仅说“你是一个助手”,还要说明专业领域、经验水平、沟通风格。“你是一名有 10 年经验的分布式系统架构师”比”你是一个技术专家”更有效。
明确输出格式:如果需要特定格式(JSON/表格/代码块),在 System Prompt 中明确说明。“每次回答先给出一句话总结,再展开详细解释”比”请详细回答”更有效。
明确边界和限制:“如果你不确定答案,请说’我不确定’,不要编造”——这类指令可以减少幻觉。
保持简洁:过长的 System Prompt 会稀释每条指令的权重。经验法则是 200-500 token 为宜。
Structured Output——格式化输出
结构化输出的意义是让AI必须按照我们希望的格式回答内容,这样可以简化我们后续对AI回复的内容的处理
在OpenAI或其他API中提供的response_format:{type:"json_object"}参数,会强制模型输出合法的JSON,在Prompt中表述JSON Schema,模型会按照 Schema 填充数据
Constrained Decoding
更可靠的结构化输出方案是约束解码(Constrained Decoding),即在生成的过程中,根据预定义的语法(如JSON Schema,正则表达式),动态的限制每一步可选的Token集合
例如,当前已生成 {"name": ",根据 JSON 语法,下一个 token 只能是字符串内容(不能是 { 或数字)。通过将不合法的 token 的概率设为 0,确保输出始终符合语法约束。
SGLang 和 Outlines(Python 库)都支持高效的约束解码。这在 Agent 开发中至关重要——Agent 的工具调用需要严格的 JSON 格式参数,任何格式错误都会导致调用失败。
ReAct
ReAct(Yao et al.,2022)是一个将推理和行为与大模型结合的范例,ReAct提示大模型为认为生成口头推理轨迹和操作,这使得系统执行动态推理来创建、维护和调整操作计划,同时还支持与外部环境(例如,Wikipedia)的交互,以将额外信息合并到推理中

图片来源于Yao et al.2022
我们会发现模型在思考的过程中多次的调用工具,最后生成结果,从本质上讲,ReAct就是让LLM通过外界工具提供的知识支持推理,进而确认下一步检索的目标
在ReAct的过程中给,他要求模型必须遵循固定的前缀(这里实际上是使用了结构化输出的技术):
- Thought: [思考过程]
- Action: [工具名称]
- Action Input: [工具参数]
- Observation: [等待外部输入]
同时强制模型在得出 Final Answer 之前,不能停止
在ReAct的论文中还涉及了如何进行ReAct过程的Prompt的示例:
问题 科罗拉多造山带东部区域延伸到的区域的海拔范围是多少?
思考 1 我需要搜索科罗拉多造山带,找到科罗拉多造山带东段延伸的区域,然后找到该区域的海拔范围。
操作 1 搜索 [科罗拉多造山带]
观察 1 科罗拉多造山带是科罗拉多及其周边地区造山运动的一段。
思考 2 它没有提到东部地区。所以我需要查一下东部地区。
操作 2 查找 [东部地区]
观察 2 (结果 1 / 1) 东部区域延伸至高平原,称为中原造山带。
思考 3 科罗拉多造山运动的东部区域延伸到高平原。所以我需要搜索高平原,找到它的海拔范围。
操作 3 搜索 [高平原]
观察 3 高平原指的是两个截然不同的陆地区域之一。
思考 4 我需要搜索高平原(美国)
操作 4 搜索 [高平原(美国)]
观察 4 高平原是大平原的一个分区。从东到西,高平原的海拔从 1800 到 7000 英尺 (550 到 2130 米) 不等。[3]
思考 5 高平原海拔高度从 1800 到 7000 英尺,所以答案是 1800 到 7000 英尺。
操作 5 结束 [1800 到 7000 英尺]
...Reflexion——自我反思
Shinn et al.(2023)提出了自我反思机制,让LLM将将“死板”的反馈(如判题机的 Fail 或具体的 Score)转化为“富有语义”的文本摘要,存入 长期记忆(Memory),也被称作 self-reflection,为下一轮中 LLM 智能体提供上下文。这有助于智能体快速有效地从之前的错误中学习,进而提升许多高级任务的性能
根据设计,自我反思由三个不同的模型组成:
- Actor(参与者):尝试对用户提出的问题进行解决
- Evaluator(评估者):对参与者的结果进行评价和打分
- Self-Reflection(自我反思):生成语言强化线索帮助参与者实现
总的来说,自我反思的关键步骤是:
- 定义任务
- 生成轨迹
- 评估
- 执行自我反思
- 生成下一条轨迹
下图展示了自我反思的智能体学习迭代优化其行为来解决决策、编程和推理等各种人物的例子
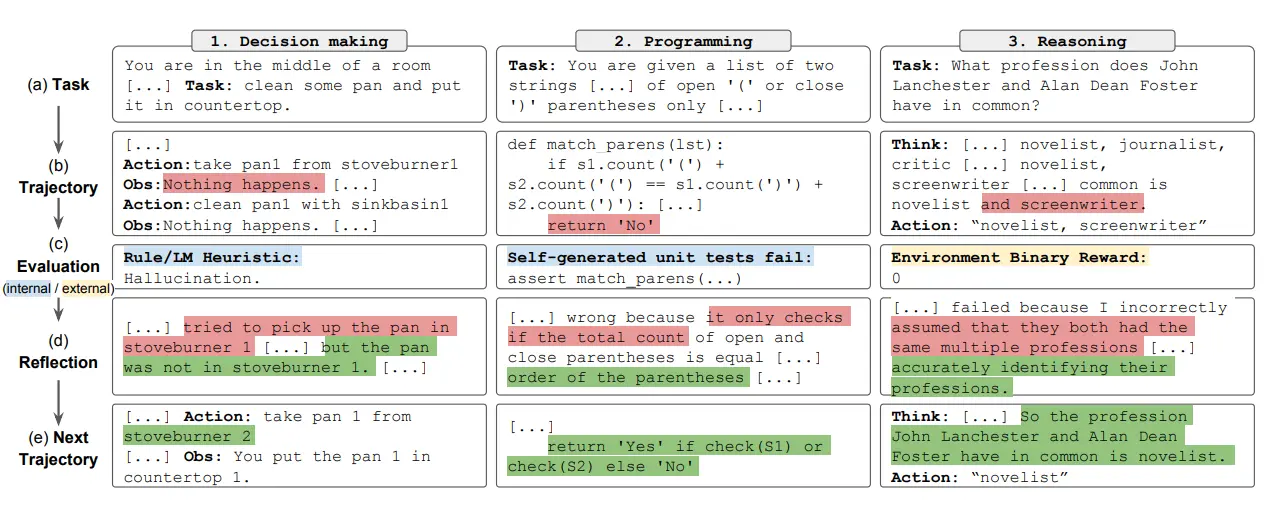
自我反思(Refelxion)通过引入自我评估、自我反思和记忆组件来拓展 ReAct 框架